
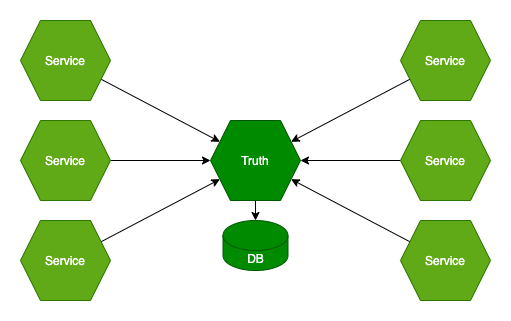
Posiadanie jednego źródła prawdy jest zdecydowanie najlepszym rozwiązaniem i do tego trzeba dążyć zawsze. Jednocześnie, należy pamiętać, że mikroserwisy powstały w konkretnym celu – w celu zapewnienie wysokiej wydajności i skalowalności. W takiej sytuacji, jedno źródło prawdy staje się wąskim gardłem i pojedynczym punktem awarii!
Cache-owane źródło prawdy?
Jednym możliwym rozwiązaniem jest wprowadzenie Cache. Czyli stawiamy np. Redisa, który jest odpytywany zawsze w celu pobrania wcześniej zapisanej wartości. Dopiero jak wartość wygaśnie (będzie zbyt stara) odpytujemy nasze źródło prawdy i odświeżamy cache.
Jest to bardzo proste i dobre rozwiązanie dla zasobów, które rzadko się zmieniają lub nie są krytyczne.
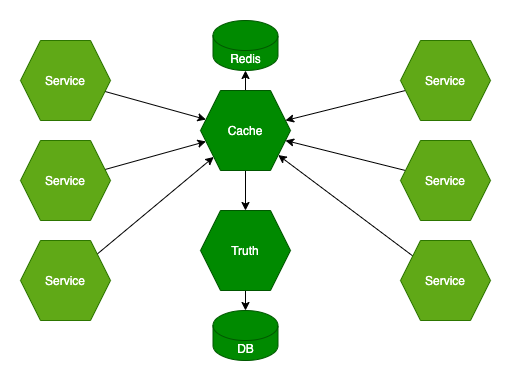
Należy uważać jednak na sytuację, w której nasza wartość w cache wygaśnie. Jest to niebezpieczny moment, ponieważ może się okazać, że wszystkie serwisy z niej korzystające będą chciały odświeżyć tę wartość i odwołają się bezpośrednio do źródła prawdy. To może spowodować przeciążenie tego komponentu i awarię na szeroką skalę. Jest to tzw. Cache Stampede i doświadczyło go już wiele firm działających w sieci (np. Facebook, który w 2010 roku z tego powodu był offline przez 4 godziny).
Nie jest możliwe wyeliminowanie tego problemu w stu procentach, można go tylko mitygować, dodając dodatkowe poziomy cache, lub wprowadzając mechanizm wyliczania wartości do samego cache, a nie do serwisów końcowych.
Read model
Kolejną możliwością, jest wprowadzenie Read modelu, czyli modelu, który służy tylko do odczytu danych. Takie rozwiązanie możemy spotkać we wzorcu CQRS, gdzie mamy oddzielne API do modyfikacji (przy użyciu wzorca Command) oraz oddzielne do odczytu.
Zazwyczaj, rozwiązanie takie jest tworzone w oparciu Eventy, na podstawie których budowany jest model do odczytu.
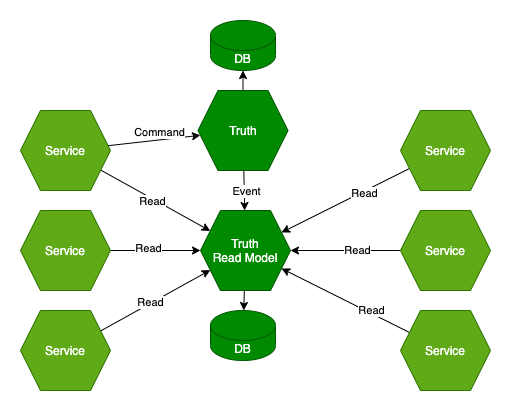
Jednak nic nie stoi na przeszkodzie, żeby na podstawie tych samych eventów, budować więcej niż jeden model danych. W takiej sytuacji jednocześnie zdejmujemy odpowiedzialność za transformacje danych z końcowych beneficjentów tych danych.
Co więcej, można pójść o krok dalej. Możemy docelowy model danych budować właśnie w serwisach końcowych, w ich lokalnych bazach danych.
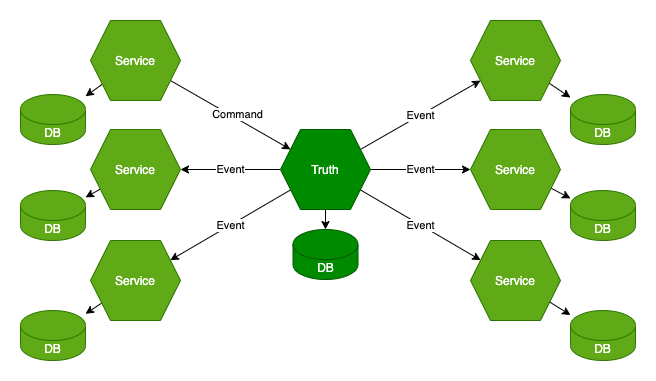
Pewnie pierwsza myśl, jaka Ci się pojawia, to to, że to zaburza zasadę jednego źródła prawdy. Tak jednak nie jest. Źródłem prawdy są tutaj eventy, na podstawie których wiedza jest rozpraszana po systemie. Jest to wiedza najbardziej aktualna i w większości sytuacji wystarczająca. Dlatego następnym razem jak będziesz projektować komunikację pomiędzy mikroserwisami, zastanów się, czy odpytywanie za pomocą REST-a jest najlepszym rozwiązaniem w Twojej sytuacji.